Laptop, desktop, czasem komputer w pracy, czasem jakiś serwer. I pliki, do których chciałbym mieć dostęp z wszystkich tych miejsc. Notatki, zdjęcia, przykładowy kod, pisane artykuły, dokumentacje, muzyka...
Całkiem sporo metod synchronizacji plików i katalogów mi się uzbierało. Co ciekawe, używam wielu z nich równocześnie.
Dla zorientowania uwagi, przyjmijmy że korzystam właśnie z laptopa i
chcę zsynchronizować treść katalogu ~/Notatki z jego treścią na
zdalnej maszynie (tu - desktopie), którą w lokalnej sieci widać
pod nazwą platon.
Rsync
Odruchowe skojarzenie ze słowem synchronizacja:
$ sudo apt-get install rsync
a potem
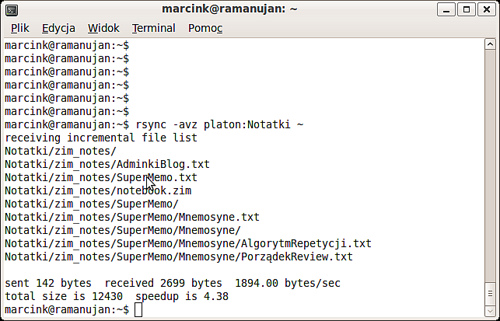
$ rsync -avz platon:Notatki ~
albo
$ rsync -avz platon:Notatki/ ~/Notatki
i wszystkie pliki z katalogu Notatki na platonie zostaną ściągnięte
(wewnętrznie będzie wykorzystane ssh).
Oba powyższe polecenia robią dokładnie to samo, a bardzo ważna jest obecność (lub nie) slasha na końcu nazwy katalogu źródłowego. Bez slasha ostatni element nazwy źródła (tu -
Notatki) zostanie doklejony do celu, ze slashem - nie. Slash oznacza: synchronizuj wszystkie pliki i katalogi z mojego wnętrza, nie mnie.Użyteczna mnemotechnika: widząc slash wyobrażam sobie, że jest po nim gwiazdka, tj. że źródłem nie jest
platon:Notatki/tylko (w rzeczywistości niedopuszczalne)platon:Notatki/*)
Później - z powrotem (dla urozmaicenia użyję pełnych ścieżek, zapis bez wiodącego slasha odnosi się do katalogu domowego):
$ rsync -avz /home/marcin/Notatki platon:/home/marcin
albo:
$ rsync -avz /home/marcin/Notatki/ platon:/home/marcin/Notatki
Bardzo przydatny program, z ślicznym, wydajnym algorytmem: nie transmituje całych plików, a jedynie różnice, potrafi wydajnie porównywać nawet duże pliki binarne (efektywność rsynca bardzo ładnie widać np. przy synchronizowaniu katalogu plików mp3 po poprawianiu znaczników). Ale....
... ale to tak naprawdę nie jest synchronizacja.
To ja muszę podać, w którą stronę ma nastąpić kopiowanie. Jeśli
podedytuję lokalnie plik Notatki/zadania.txt, a potem zrobię
$ rsync -avz platon:Notatki ~
moja wersja zostanie niemiłosiernie nadmazana ściągniętą starszą wersją. Oczywiście tym bardziej nie ma mowy o obsłudze sytuacji, gdy część plików była edytowana tu, a część tam.
Dlatego rsync nadaje się głównie do dystrybucji zmian: obsługi
sytuacji, w której pliki są dodawane i edytowane zawsze w tym samym
głównym miejscu, a potem są propagowane dalej (np. przy rozrzucaniu
po kilku maszynach nowej wersji programu czy nowego zbioru stron
HTML). A nawet w tym scenariuszu pozostaje jeden problem - nie jest
propagowany fakt usunięcia pliku.
rsync jest też bardzo użytecznym programem do kopiowania
czy przenoszenia danych między systemami plików, migrowania
ich na nowy dysk itp (w tej roli wspominałem
go niegdyś w artykule o konfigurowaniu prostego RAID).
Unison
Prawdziwą synchronizację obsługuje Unison. Bardzo pomysłowy program, który zawsze (dla każdego pliku z osobna) wie, na której z maszyn nastąpiła edycja, wie czy plik obecny tylko z jednej strony został nowo dodany, czy może usunięty, wreszcie - zauważa konflikty (tj. sytuacje, gdy ten sam plik był niezależnie edytowany na obu maszynach).
Instalacja (do przeprowadzenia na obu maszynach)
$ sudo apt-get install unison-gtk
albo (wersja command-line):
$ sudo apt-get install unison
Uruchamianie:
$ unison-gtk /Notatki ssh://platon/Notatki
albo (przykład dla pełnej ścieżki):
$ unison-gtk /Notatki ssh://platon//home/marcin/Notatki
W przeciwieństwie do rsynca, nie ma znaczenia z której maszyny uruchamiam synchronizację i w jakiej kolejności podaję katalogi
Przy pierwszym uruchomieniu (dla danej pary katalogów) pojawia się odpowiednie ostrzeżenie, trzeba je po prostu zatwierdzić.
Program działa dwufazowo. Najpierw pojawia się okienko z listą wszystkich rozbieżności między synchronizowanymi katalogami i sugerowanymi akcjami:
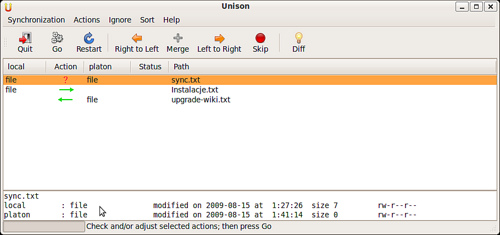
Zielone strzałki oznaczają, że dany plik lub katalog zostanie skopiowany w podanym kierunku. Znak zapytania - że był modyfikowany z obu stron (mamy konflikt) i Unison nie wie, jak postąpić.
Przeglądam tą listę i w razie potrzeby koryguję akcje. Najważniejszy skrót klawiszowy to / (zignoruj tym razem ten plik), dany plik zostanie oznaczony znakiem zapytania i będzie w trakciej tej sesji pominięty. Klawisze < i > nakazują odpowiednio kopiowanie w lewo i w prawo. Jest też parę innych opcji, np. zapamiętanie, że dany plik ma być ignorowany na stałe. Wszystko to oczywiście można też wybierać z menu.
Gdy całość wygląda poprawnie, klikam przycisk Go i zaczyna się druga faza - właściwe kopiowanie.
Kopiowanie używa algorytmu rsync-a, jest równie wydajne.
Program oznacza ptaszkami, które pliki zostały już obsłużone, na koniec w pasku statusu pojawia się tekst Synchronization Complete.
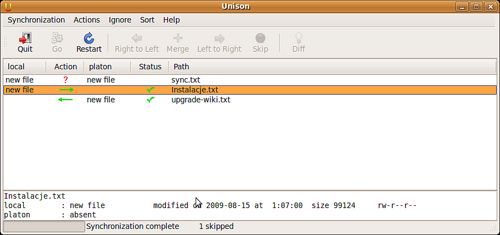
Uruchamianie terminalowe wygląda podobnie, tyle że program po prostu pyta o każdą rozbieżność po kolei.
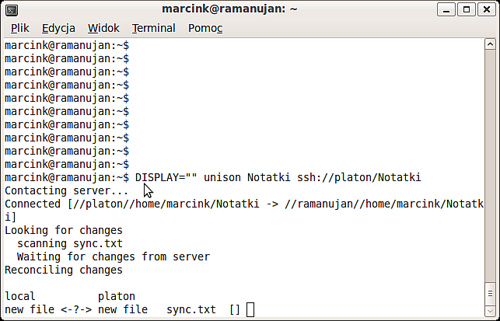
Obowiązują te same skróty klawiszowe, co w wersji graficznej, pełna lista jest wyświetlana po wciśnięciu znaku zapytania.
Skąd Unison wie, jak traktować zmiany?
Przy pierwszym uruchomieniu - nie wie, po prostu chce kopiować pliki istniejące tylko na jednej z maszyn, ignoruje pliki identyczne z obu stron, a każdą sytuację gdy plik o tej samej nazwie istnieje na obu maszynach ale ma różną zawartość raportuje jako konflikt.
Później - dysponuje wiedzą zapisywaną w katalogu
~/.unison, gdzie
notowane są informacje historyczne (nazwy plików i sumy kontrolne
ich treści). Dzięki temu program po prostu może porównać bieżący stan
katalogu z tym, co było w nim poprzednio, zatem wie, czy jakiś plik
został dodany, usunięty lub zmodyfikowany
Conduit
Conduit jest interesującym programem rozwijanym w celu synchronizacji różnorodnych danych (nie tylko plików). Rozumie niektóre aplikacje (np. umie synchronizować notatki tomboya czy książki adresowe), współdziała z serwisami sieciowymi (np. może wgrywać zdjęcia na Flickra czy Picasę albo je stamtąd pobierać). Przykryte jest to wszystko dość ciekawym (wizualizacja reguł kopiowania w formie diagramów), choć nieco konfudującym GUI.
W tej chwili Conduita nie używam, więc z dłuższą recenzją się wstrzymam, planuję kiedyś przyjrzeć mu się dokładniej.
System zarządzania wersjami
Dla kodu źródłowego, pisanych dokumentów czy notatek idealnym rozwiązaniem jest użycie systemu zarządzania wersjami.
Najwygodniejsze są narzędzia DVCS, nie wymagające wydzielania i konfigurowania dedykowanego serwera. Preferuję Mercuriala, ale GIT czy Bazaar nie powinny być gorsze.
Przy tej technice, po początkowym sklonowaniu, cała
synchronizacja ogranicza się do hg pull i ewentualnie hg merge.
Szerzej nie będę tego tu opisywał, bo rzecz niczym się
nie różni od używania Mercuriala w małym zespole.
Jedyny problem: DVCS-y kiepsko się nadają do obsługi dużych
plików (np. Mercurial zaleca ograniczenie rozmiaru do 10MB)
i bardzo dużych drzew. Chodzi głównie o algorytmy wyliczania zmian,
alokujące w RAM 4-5 razy rozmiar commitowanego pliku.
Dochodzi też dyskowy koszt drugiej kopii przechowywanej w podkatalogu
.hg. Dlatego drzewo zdjęć, plików MP3 czy filmików lepiej zsynchronizuje
Unison.
Ale do wszelkiej maści pisanego tekstu - idealne rozwiązanie.
Zewnętrzne serwisy (dyski sieciowe)
Rozwiązanie dla leniwych: wirtualne dyski automatycznie synchronizujące się przy pomocy specjalizowanej sieciowej usługi.
Moja ulubiona to Dropbox. Zachwalałem już go kiedyś pod koniec artykułu o Mnemosyne, dlatego tutaj przypomnę tylko, że unikalną wartością Dropboxa jest zachowywanie historii edycji pliku, a co za tym idzie, możliwość cofnięcia się do poprzedniej (czy jeszcze starszej) wersji. Do 2GB danych usługa jest bezpłatna.
Używałem też JungleDisk, którego miłą cechą jest możliwość zapisu na moim storage Amazon S3, możliwość działania bez GUI (montowałem JungleDiskowy dysk z VPS), a także opcja szyfrowania zapisywanych danych (które pozostają dzięki temu ukryte przed dostawcą). Niestety, chyba wycofali się z możliwości zakupu programu bez comiesięcznej opłaty abonamentowej (w zeszłym roku można było zakupić program i - o ile nie używało się przyspieszającej działanie usługi Plus - dalsze wydatki ograniczały się do płacenia Amazonowi za transfer i dysk).
JungleDisk to nie do końca synchronizacja, z założenia na lokalnej maszynie nie muszą być dostępne wszystkie pliki (w szczególności wirtualny dysk rozmiaru setek megabajtów może być dostępny mimo lokalnego ograniczenia miejsca do np. 10MB).
Poza synchronizacją
Synchronizacja nie wyczerpuje możliwości dzielenia plików i danych.
Opcją nowomodną jest cloud, czyli przechowywanie danych na serwerach sieciowych i używanie ich przez przeglądarkę. Przykładem mogą być zakładki, listy rzeczy do zrobienia, poczta, notatki, proste dokumenty.
Nie można też zapominać o tradycyjnej metodzie, czyli zwykłym montowaniu zdalnego katalogu przy pomocy Samby lub NFS. Oczywiście tak można postępować tylko w sieci lokalnej i tylko pod warunkiem stałego działania komputera funkcjonującego jako serwer.