Mam w domu sporą paczkę Fantastyk, Science Fiction i podobnych czasopism. Coraz trudniej znaleźć dla nich jakieś miejsce, żona regularnie wspomina o zaletach zbioru makulatury a mi żal... Może nie całości - słabych opowiadań też niestety sporo - ale w niemal każdym numerze jest jakiś tekst, który chciałbym zachować.
Literackie opowiadanie wręcz idealnie nadaje się do czytania na czytniku ebooków, stąd oczywisty pomysł, by najwartościowsze teksty poskanować (dodatkowo w przypadku gazety jest to mniej pracochłonne niż dla książki). Przejrzałem trochę dostępnych pod moim Linuksem narzędzi i wstępnie wypracowałem dość obiecujący schemat pracy.

Efektem opisanych niżej działań są (dla każdego opowiadania):
-
plik
.djvuzachowujący wizualną formę zeskanowanego czasopisma - ograniczonej jakości ale bardzo niewielki (100-200kB) a pozwalający w razie potrzeby wyjaśnić wątpliwości przy dopracowywaniu tekstu (np. zweryfikować położenie końców rozdziałów, poprawić źle rozpoznane słowo itd), -
plik
.txtz tekstem (który - po przejrzeniu - można skonwertować do ebooka lub opracować w dowolny inny sposób).
Nim przejdę do opisu mojej metody, wzmianka o alternatywie.
Narzędzie, które mi się nie spodobało
... to gscan2pdf. Jest to dość ciekawy program organizujący w ramach
jednego GUI komplet operacji począwszy od skanowania po tworzenie
pliku .pdf czy .djvu.
Program przetestowałem ale nie byłem z niego zadowolony. Tworzone
pliki .djvu były bardzo duże (skan wysokiej rozdzielczości,
przydatny do ewentualnego ponownego drukowania ale na moje potrzeby
zdecydowanie przesadny), choć był realizowany OCR, nie powstawał
osobny plik tekstowy (efekty zapisywane były tylko jako tekstowa
warstwa w .djvu), zdarzały się przypadki obcięcia części tekstu wraz
z marginesem. A co najgorsze, proces skanowania okazał się bardzo
uciążliwy - po włożeniu kartki musiałem czekać aż zakończą działanie
programy analizujące zeskanowaną stronę i dopiero wtedy mogłem
skanować następną, co trwało i trwało.
Na doczepkę program nie potrafił otworzyć pliku .djvu
który sam zapisał (program jest zorientowany bardziej na tworzenie .pdf).
Niezależnie od powyższego zachęcam do obejrzenia, jeśli komuś efekty
działania gscan2pdf się spodobają, zapewnia on dalece zautomatyzowaną
obsługę całej operacji i całkiem czytelny interfejs.
Uwaga specyficzna dla skanera (mam prosty i tani Epson Perfection): miałem kłopoty ze zmuszeniem
gscan2pdfdo czekania na wciśnięcie przycisku na skanerze (którym sygnalizuję, że włożyłem następną kartkę). Opcja wait for button pojawiła się dopiero gdy zmieniłem (w preferencjach) frontend nascanimage-perl.
Instalacja potrzebnych narzędzi
Większość potrzebnych mi narzędzi jest w Ubuntu w pakietach:
sudo apt-get install unpaper imagemagick \
minidjvu ocrodjvu libmagick++-dev
Jedno instalowałem z PPA (w Ubuntu, przynajmniej 10.04, jest starsza
wersja wymagająca dodatkowego konwertowania plików graficznych do .bmp
i przez to komplikująca pracę):
sudo add-apt-repository ppa:gezakovacs/pdfocr sudo apt-get update sudo apt-get install cuneiform sudo apt-get upgrade
(potrzebna jest wersja 0.9.0 lub nowsza)
Skanowanie
Mam prosty skaner Epsona (Perfection 350). Próbowałem różnych technik skanowania (min. kiedyś zafundowałem sobie VueScana, którego później porzuciłem wobec problemów z konfiguracją na 64-bitowym systemie i do którego być może niedługo wrócę skoro takowa wersja się ostatnio pojawiła, program jest całkiem przyjemny w użyciu) ale ostatecznie najprostszy okazał się epsonowy iscan (którego instalacji wszelkie inne warianty tak czy siak wymagają).
Uruchamiam ten program z opcjami:
- enable Start button
- image type: black & white document
- 400 dpi
- greyscale (zapewne starczyłoby monochrome ale różnicy czasu skanowania nie widzę a ewentualne ilustracje, gdybym chciał je zachować, będą lepszej jakości).
Klikam przycisk Scan, wybieram schemat nazw page-%d.png każąc
zapisać efekty w nowym pustym katalogu, który nazywam od nazwy
skanowanego tekstu a potem po prostu przekładam kartki pukając
w przycisk startowy skanera.
Ważny (dla mnie) element: nie muszę przeplatać przekładania kartek z wykonywaniem jakichś operacji na komputerze a czas skanowania jest ograniczony jedynie tempem działania skanera. W ten sposób ta najbardziej męcząca operacja przebiega stosunkowo sprawnie.
Efektem jest seria plików .png - sporych, każdy wielkości ok. 10MB.
Preprocessing
Konwertuję zeskanowane pliki do .pbm (monochromatyczny format
bitmapowy rozumiany przez dalsze narzędzia):
cd katalog_ze_skanami for i in *.png; do convert $i `basename $i .png`.pbm; done
(powyższe wywołuje convert blabla.png blabla.pbm dla wszystkich
plików .png w bieżącym katalogu, program convert pochodzi z ImageMagic
i pozwala na szybkie konwertowanie, skalowanie czy obcinanie plików
graficznych).
Następnie filtruję te pliki przy pomocy programu unpaper.
Poniższa operacja chwilę trwa (na moim komputerze ok. 10 sekund na plik),
przy większej liczbie stron można ją zostawić i zająć się czymś innym.
unpaper page-%03d.pbm unp-%03d.pbm
(tu pętli shellowej nie trzeba pisać, sam unpaper iteruje po kolejnych plikach pasujących do zadanej maski).
Unpaper to zbiór rozmaitych filtrów poprawiających jakość tekstu skanowanego z papieru. Najbardziej wyraźnym efektem działania jest wyrównanie położenia.
Uwaga: efekty pracy unpaper trzeba zweryfikować. Zdarzyło mi się, że
(dla nieco nierówno położonej przy skanowaniu kartki) program nieprawidłowo
zdiagnozował położenie kolumn i obciął część tekstu.
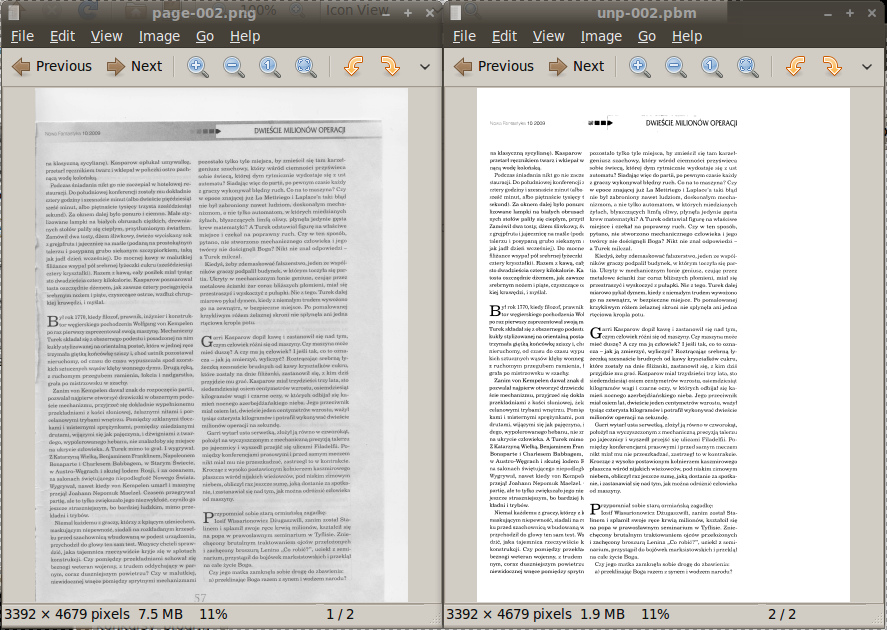
W razie problemów mogą pomóc ręczne opcje, np. w powyższym wypadku
unpaper -vv --overwrite \
--pre-shift 200,0 page-002.pbm \
unp-002.pbm
(kazałem po prostu przesunąć obrazek w lewo o 200 pikseli przed przeliczaniem, owo 200 dobrałem na oko - lewy margines miał około 70 pikseli a prawy około 420, wstępne przesunięcie o 200 z grubsza je wyrównywało).
Przy używaniu starego cuneiform dochodzi jeszcze konwersja do
.bmp. Przy cuneiform 0.9 poniższe nie jest potrzebne:
for i in unp*.pbm; do \
convert -format MONO $i `basename $i .pbm`.bmp; done
Budowa pliku DJVU
Proste polecenie:
minidjvu --lossy unp*.pbm result.djvu
Dla niewielkich tekstów trwa to parę-paręnaście sekund.
Efektem jest plik result.djvu ze skanem nieszczególnie wybitnej
jakości ale wystarczająco czytelnym, by sprawdzić jak to wyglądało w
oryginale (gdzie były tytuły rozdziałów, czy ta podejrzana siódemka
była elementem tekstu czy stopką strony itd itp) a niewielkim (dla
parunastu stron 100-200kB).
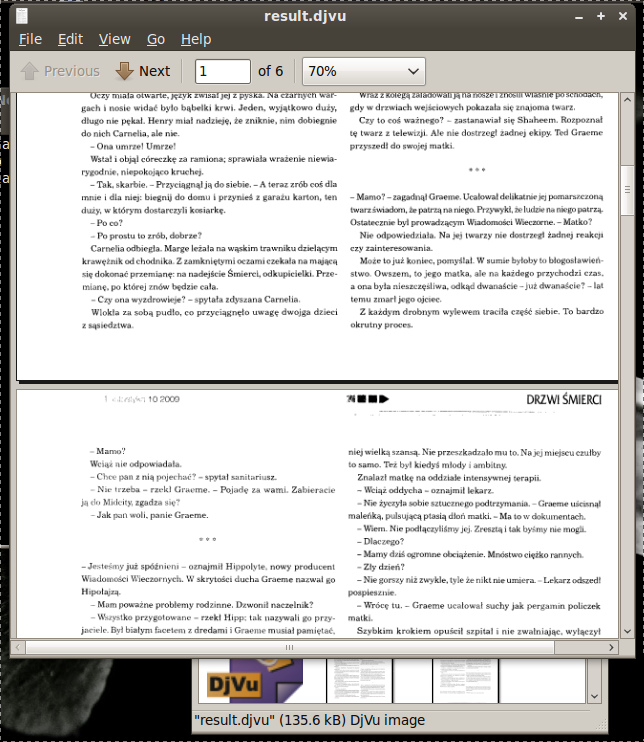
Ciekawostka: gscan2pdf przetwarzając to samo opowiadanie stworzył
plik trochę czytelniejszy i lepszej rozdzielczości ale wielkości ...
niemal 10MB.
Alternatywnym do
minidjvuprogramem przetwarzającym obrazki na.djvujestcjb2(także dostępny w pakiecie,apt-get install djvulibre-bin). Nie testowałem go jeszcze.
OCR
Z kilku programów OCR dostępnych w pakietach (tesseract, ocropus)
zdecydowanie najlepiej wypadł cuneiform - w szczególności dzięki
dobrej obsłudze polskich znaków (program jest dziełem rosyjskich
programistów).
Proste wygenerowanie tekstu każdej strony:
for i in unp*.pbm; do
cuneiform -l pol -f smarttext \
-o `basename $i .pbm`.txt $i
done
Powyższa pętla woła polecenia takie jak
cuneiform -l pol -f smarttext -o unp-001.txt unp-001.pbm,
powstają pliki unp-001.txt, unp-002.txt itd. Opcja -f
smarttext znakuje akapity pustymi wierszami, jest też kilka
innych wariantów wyniku (min. html, patrz cuneiform -f).
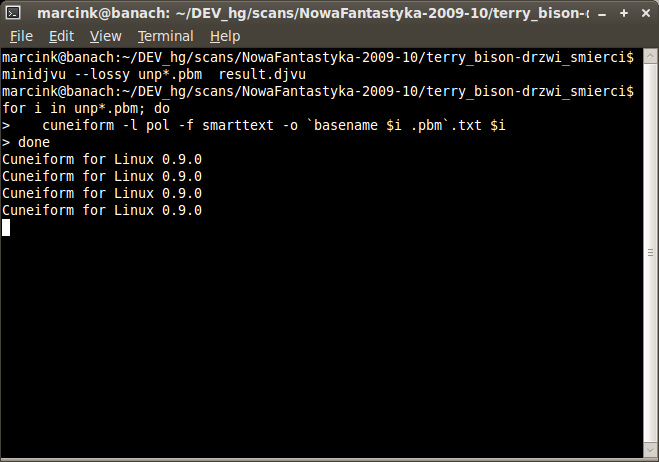
Zdarzyło mi się, że
cuneiformwysypał się brzydko (buffer overflow detected) w trakcie przetwarzania jednej ze stron. Pomogło usunięcie (wycięcie) z pliku "wrzutki" - obramowanej tabelki z informacjami o autorze.
Tak powstałe pliki łączę w jeden (dodając dla wygody oznaczenia końca strony):
echo "" > result.txt
for i in unp*.txt; do
cat $i >> result.txt
echo -e '\n-----------------------\n' >> result.txt
done
(zamiast ciągu minusów może być coś innego, np. sensownym
niewidzialnym znaczkiem może być formfeed:
echo -e '\f' >> result.txt)
Możliwe jest też uruchomienie OCR ze skanowaniem DJVU i zapisywaniem
tekstu bezpośrednio w tymże pliku .djvu (format obsługuje dołączanie
tekstu, nie wydaje mi się ta opcja szczególnie przydatna ale zachowuje
całość w jednym pliku). Parę miesięcy temu używałem do tego polecenia:
ocrodjvu --in-place \
--engine=cuneiform --language=pol result.djvu
ostatnio przestało mi ono działać (prawdopodobnie niezgodność wersji
ocrodjvu i cuneiform) ale notuję do ewentualnego zapamiętania i ponownego sprawdzenia.
Tekst zanurzony wewnątrz .djvu daje się odczytać przy pomocy
djvutxt result.djvu
Końcowa edycja
Powstały plik tekstowy wymaga jeszcze przejrzenia - zwykle zawiera trochę śmieci (zwłaszcza w miejscach takich jak nagłówki, stopki czy początki rozdziałów), miewa błędy w dzieleniu (lub nie) akapitów itd itp.
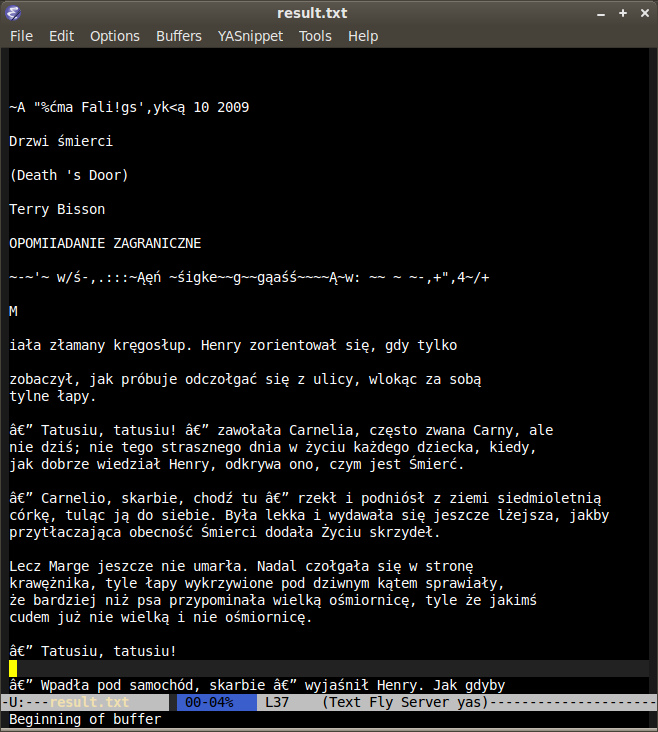
Zazwyczaj wystarcza parę operacji szukaj i zamień (np. powyżej charakterystyczne sekwencje trzeba zamienić na myślniki), wycięcie śmiecia powstałego w nagłówkach czy stopkach oraz przeczesanie spellcheckerem. W wątpliwych miejscach przydatny może być (o ile już wyrzuciłem papierową wersję) plik .djvu.
Ostatnim etapem jest konwersja na .epub ale o tym
postaram się napisać kiedy indziej.
Końcowy efekt (w formie .txt oraz .djvu a później także .epub) ląduje
w Calibre.
Podsumowanie
Opis jest dosyć długi ale pracochłonne są tak naprawdę tylko dwie operacje: przekładanie kartek w skanerze i końcowe porządkowanie tekstu w edytorze, reszta dzieje się automatycznie (docelowo zapewne ją sobie zamknę w jednym skrypcie). Porządkowanie tekstu można zresztą odłożyć na później.
Nie twierdzę, że jest to metoda idealna - opisuję ją na podstawie paru dni testów i kilku opracowanych opowiadań, mogłem przeoczyć jakieś poręczne narzędzie. Mój specyficzny cel: uzyskanie tekstu (a nie np. PDFa z bitmapami) i niewielkiego pliku z wizualizacją oryginału - realizuje satysfakcjonująco.
Jest to, jak widać, trochę pracy. Gdyby któreś z czasopism zdecydowało się zaoferować elektroniczną prenumeratę na pewno bym ją poważnie rozważył...