Projekty czysto internetowe są najczęściej planowane i budowane od góry do dołu, w spójny i jednolity sposób. Informatyka biznesowa wygląda inaczej - obrazek składany jest z kilku, kilkunastu, a bywa że i kilkudziesięciu systemów, aplikacji, modułów. Interfejs webowy (albo i parę), kilka aplikacji back-office dla różnych grup pracowników, system(y) ewidencji zgłoszeń, pakiet IVR i/lub call-centre, kanał mobilny, moduł autoryzacyjny, główna baza klientów czy towarów, komponenty wymiany danych z firmami zewnętrznymi, procedury raportujące, pakiety analityczne, podsystem windykacyjny, obsługa masowych wydruków i wysyłek, system finansowo-księgowy, oprogramowanie specjalizowanych urządzeń (od robotyki przemysłowej po bankomaty), ... Wszystko to kupowane i budowane przez lata, od wielu dostawców, a potem spinane na różne sposoby.
O specyfice tego spinania może w przyszłości troszkę popiszę, ale dziś proste wspomnienie techniczne - jak sobie dwa systemy rozmawiały. Parę lat temu to było.
Krajobraz
Pierwszy system - nazwijmy go X - realizował proste ale mające ważne konsekwencje operacje. No, powiedzmy szczerze - wypłacał pieniądze. A w celu sprawdzenia czy można i zapisania informacji co komu wydano, komunikował się z systemem Y.
System Y (tak naprawdę złożona kombinacja różnych elementów, ale dla tego artykułu to nieistotne) sprawdzał co trzeba, rejestrował co trzeba, aktualizował co trzeba i odsyłał odpowiedź.
Między X i Y był protokół opisujący sposób komunikacji. Dość niebanalny, uwzględniający kilka scenariuszy. Podstawowy był nieskomplikowany:
- X wysyłał do Y inicjalne żądanie zapisz taką a taką transakcję,
- Y robił co do niego należało i odpowiadał - albo OK, wszystko w porządku albo nie, tego nie wolno,
- X zależnie od odpowiedzi obsługiwał klienta lub mu odmawiał.
Jak na razie słodko. Ale ... co miał zrobić X, jeżeli Y w ogóle nie odpowiedział? Zgłosić błąd? A co jeśli Y zapisał informację, tylko odpowiedź jeszcze nie nadeszła lub zaginęła po drodze? Czekać? Ale jak długo? I co potem?
To także było dokładnie obmyślone - w takiej sytuacji X odmawiał klientowi obsługi, po czym przesyłał do Y nakaz wycofania wcześniej zleconej operacji - o ile do niej doszło. To samo działo się, gdy X z jakichś przyczyn nie zdołał dokończyć obsługi już po otrzymaniu odpowiedzi od Y.
Ba - ale i wycofanie mogło się nie udać, Dlatego X miał w razie potrzeby powtarzać ten nakaz wielokrotnie, do skutku. Y z kolei implementował odpowiedni algorytm wykrywania i obsługi zduplikowanych zleceń (nawet gdyby pojawiło się ich kilka równocześnie czy przyszły w dziwnej kolejności).
Było tam jeszcze trochę innych elementów, np. transakcje wymuszane (Y-ku musisz zapisać, już dałem), z powtarzaniem na tej samej zasadzie.
Technikalia
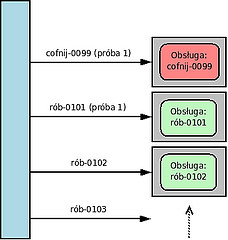
Technicznie X po prostu ustawiał timeout na kierowane do Y żądania. Jeśli po zadanej ilości sekund nie dostał odpowiedzi, raportował użytkownikowi błąd i wysyłał nakaz cofnięcia. Jeśli teraz przez zadany czas nie przyszła żadna odpowiedź, słał go jeszcze raz. I jeszcze raz. I jeszcze raz. Do skutku. Analogicznie obsługiwał ponawianie operacji wymuszonych.
Y z kolei miał pewną pulę procesów roboczych obsługujących przychodzące od X żądania. First in, first served.
Tu jest dobry moment na zastanowienie się nad zaletami i wadami takiego podejścia.
No i tak sobie działały. X wysyłał, Y obsługiwał, do tego był skonfigurowany ze sporym zapasem.
Kryzys
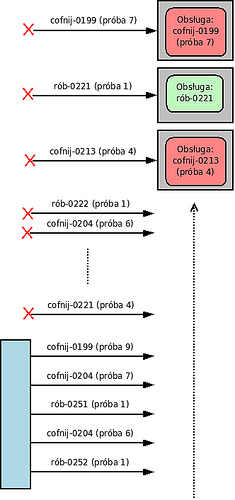
Pewnego dnia wystąpiło chwilowe przeciążenie (X wygenerował krótkotrwały ruch poważnie przekraczający założenia). Nic wielkiego ale kilkanaście żądań nie zdążyło się wykonać. X zgodnie z protokołem wysłał żądania cofnij ale - ponieważ równocześnie poszło też trochę nowych komunikatów - Y wyrobił się na czas tylko z częścią z nich. X znowu powtórzył... Do tego, pojawiły się nowe żądania (użytkownicy, którzy dostali błędy, zrobili oczywistą rzecz - spróbowali jeszcze raz).
Po parunastu minutach, z punktu widzenia klientów, nic już nie działało - choć oba systemy pracowały pełną parą. I mimo upływu czasu stan ten trwał.
Co się działo? Wszystkie procesy Y zajmowały się obsługą żądań, które z punktu widzenia X były już przeterminowane. O czym Y oczywiście nie wiedział.
Tu jest dobry moment na wymyślenie, jak to rozplątać.
Rozwiązanie
Z różnych względów jakiekolwiek modyfikowanie systemu X (nie mówiąc już o samym protokole) nie wchodziło w grę. Dlatego rozwiązania trzeba było szukać po stronie Y, a okazało się nim dodanie swoistej kontroli ruchu. Był to moduł, który w maksymalnym możliwym tempie odbierał wszystkie komunikaty i budował kolejkę zleceń czekających na przetwarzanie, a do tego kontrolował jej rozmiar - i przy przekroczeniu limitu, wywalał najstarsze z oczekujących żądań do śmieci.
Zadziałało znakomicie, choć mechanizm nie był w pełni naturalny, bardziej logiczne byłoby wprowadzenie zmian po stronie X – rosnących (zamiast stałych) interwałów, może limitowania ilości równoczesnych żądań, może priorytetów czy nawet osobnego kanału komunikacji dla powtórek.
Nauczka
Scenkę przypominam, bo podejście spróbuj, ustaw timeout, powtarzaj w razie niepowodzenia jest całkiem częste - bądź co bądź piszemy coraz więcej aplikacji komunikujących się przez sieć (także rozległą), zwykle bez żadnej semantyki transakcyjnej. Co więcej, nawet gdy aplikacje same z siebie nie mają semantyki ponawiania, użytkownicy siedzący przy przeglądarkach reagują na błędy a nawet powolne działanie przeladowywaniem stron, powtórnym zatwierdzaniem formularzy i tym większą ilością żądań. Dlatego zaplanowana technika obsługi przeciążeń może być bardzo przydatna.
Warto też zauważyć, że wcale nie było tu oczywiste kto - a nawet, czy ktoś w ogóle - jest winny. System X realizował logiczny i konieczny algorytm nie dopuszczający do sfałszowania danych. System Y przetwarzał żądania z średnią wydajnością zauważalnie przekraczającą wymagania. Problem pojawił się na punkcie styku - i właśnie taką naturę ma bardzo, bardzo wiele realnych błędów.
Wreszcie, punkcik do pamiętania dla planujących testy - co się dzieje, gdy system jest przeciążony; co, gdy któryś z komponentów jest chwilowo niedostępny; co, gdy wystąpi krótkotrwała nawała żądań; ...? Wiadomo, że całego ruchu w takiej sytuacji nie obsłużymy - ale czy uda się choć część?