Jak właściwie poukładać kod źródłowy przy pisaniu bibliotek i skryptów w Pythonie? Problem wcale nie jest trywialny, stosowanych konwencji jest wiele, modułów utrzymywanych i dystrybuowanych jako chaotyczne paczki plików źródłowych - jeszcze więcej.
Opisuję niżej konwencję dobrze dopasowaną do pracy z użyciem wirtualnych środowisk pythona oraz SetupTools. Pasuje ona także do PyDev, czyli modułu pythonowego dla Eclipse. Zbieram tu techniki podejrzane w różnych cudzych bibliotekach, w sporej części opisane w książce Tereka Ziade.
Scenariusz
Piszę i utrzymuję wiele bibliotek pythonowych (a także skryptów/programów). Każda z nich posiada kod źródłowy, pliki testów, dokumentację, przykłady użycia, pliki obsługujące budowę dystrybucji.
Niektóre z bibliotek korzystają z siebie nawzajem ale zasadniczo są niezależne, każda ma własny cykl życia.
Ogólna struktura
Nazewnictwo
Dla uniknięcia konfliktów nazw, wszystkie moduły będą miały mój
prefiks - mekk.. Stworzę biblioteki mekk.chess,
mekk.feeds, mekk.orgfile, mekk.xmind, mekk.nozbe2xmind itp.
Innymi słowy, używając swojego kodu będę pisał np.
import mekk.chess
co znacznie zmniejsza szanse na konflikty
(wysoce prawdopodobne, gdybym nazwał swoje moduły po prostu chess
czy feeds).
Jaki prefiks stosować? Zależy. Może być to nazwa firmy lub jej skrót
(jak Ft.* dla modułów firmy Fourthought), może być nazwa dużego
wielomodułowego projektu (na wzór zope.* czy lxml.*), może - jak w
moim przypadku - prywatna nazwa nawiązująca do pseudonimu lub
domeny. Grunt, by dawała realną szansę na unikalność.
Katalog developerski
Często stosowane automatyczne podejście owocuje następującą strukturą katalogów:
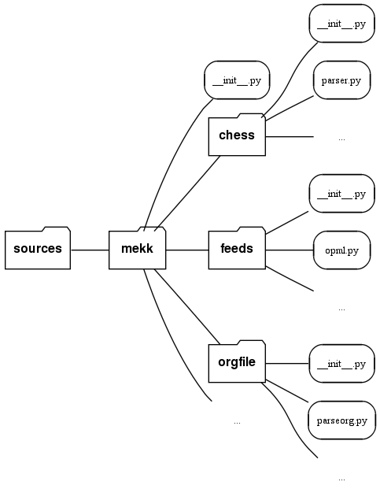
Nie jest ono dobre z kilku powodów:
-
wymusza traktowanie wszystkich bibliotek jako jednej całości, choć nie zawsze ma to sens,
-
nie daje żadnego dobrego miejsca, w którym można by umieścić testy, dokumentację, przykłady,
-
zupełnie nie widać, gdzie umieścić pliki sterujące buildem, z
setup.pyna czele.
Dlatego lepsze jest inne rozwiązanie:
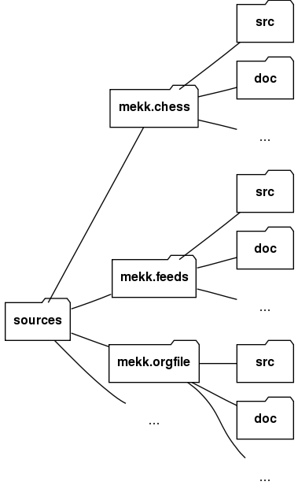
Każdy z modułów ma swój indywidualny podkatalog o specjalnej strukturze.
W niektórych środowiskach nazwy z kropkami są kłopotliwe. Konwencja ta nie jest obowiązkowa, równie dobrze możemy mieć
mekk_chess,mekk_feedsitd. Albo dowolne inne nazwy, nie mają one znaczenia dla wyszukiwania modułów.
Struktura kodu pojedynczego modułu
Co się dzieje w ramach każdego modułu?
Weźmy za przykład mekk.chess. Będziemy tu mieć coś takiego:
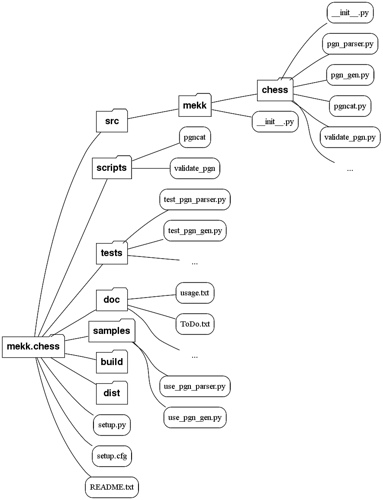
Mamy zatem podkatalogi src, scripts, doc, tests, samples.
Mamy plik setup.py w głównym katalogu (niekiedy uzupełniony przez
setup.cfg).
Cały katalog mekk.chess jest zamkniętą całością, niezależną od reszty świata,
w szczególności mogącą podlegać niezależnemu wersjonowaniu
(u mnie jest to osobne repozytorium Mercuriala).
Katalog src
Katalog src zawiera właściwy kod pythonowy modułu, z uwzględnieniem
odpowiedniej hierarchii podkatalogów. Zawiera zatem podkatalog mekk,
w nim podkatalog chess, a tu właściwy kod.
Plik mekk/__init__.py ma specjalne znaczenie i następującą treść:
try:
__import__('pkg_resources').declare_namespace(__name__)
except ImportError:
from pkgutil import extend_path
__path__ = extend_path(__path__, __name__)
Ten nieco magiczny fragment (wraz z dodatkową klauzulą w setup.py, o której
niżej) to tak zwana konwencja namespace, pozwalająca tej samej
nazwie nadrzędnego katalogu pojawiać się w wielu niezależnych bibliotekach.
W tym przykładzie pakietem namespace jest mekk.
Gdyby powyższy plik
__init__.pybył pusty, pojedyncza biblioteka działałaby poprawnie ale ... tylko pojedyncza. Po zainstalowaniu - powiedzmy -mekk.chessorazmekk.feeds, python znalazłby tylko jeden z tych modułów, drugiego (i dalszych) - nie (bo znalazłby tylko pierwszy z katalogów o nazwiemekk).
Plik mekk/chess/__init__.py może być pusty, częściej będzie zawierał
importy najważniejszych funkcji i klas. Na przykład:
from pgn_parser import PgnParser from pgn_gen import PgnGenerator
Zdarza się, że programiści umieszczają w __init__.py większe porcje
kodu (klasy, funkcje, stałe). Uważam to za nieeleganckie - zamiast
pisać kod w somemodule/__init__.py można go umieścić w somemodule.py.
Do tego dość łatwo pojawiają się problemy z kolejnością przetwarzania
w trakcie importów.
Pozostałe źródła ... - cóż, kod.
Wiele publicznie dostępnych modułów pythonowych stosuje układ kodu bardzo podobny do tego, który tu opisuję - ale bez katalogu
src, z umieszczeniem korzenia kodu (tu - katalogumekk) bezpośrednio w głównym katalogu biblioteki.Używanie
srcma sens z kilku powodów:
- mamy wyraźniejszą separację źródeł od pozostałych plików, min. trudniej o omyłkowe zabranie zbędnych plików do dystrybuowanego pakietu,
- unikamy wrzucania do ścieżki przeszukiwania Pythona podkatalogów pomocniczych (choćby
samplesczytests),- jest to konwencja zgodna z wymaganiami PyDev, jednego z popularniejszych środowisk do kodowania w Pythonie (po ustawieniu dla
srcflagi Python Source folder będzie automatycznie dodany do ścieżki przeszukiwania przy uruchamianiu i debuggowaniu wewnątrz Eclipse).
Katalog scripts
Katalog scripts jest wykorzystywany tylko, gdy moduł zawiera skrypty
lub programy - rzeczy przeznaczone do uruchamiania jako gotowe
aplikacje.
Instalator skopiuje je do katalogu umieszczonego w PATH (/usr/bin lub
/usr/local/bin na Linuksie, C:\Python\Scripts na Windows).
Dobrym zwyczajem jest, by skrypty te były bardzo krótkie, ot na przykład:
import mekk.chess.run_pgn_validator mekk.chess.run_pgn_validator.main()
albo nawet
import mekk.chess.run_pgn_validator
W obu wypadkach to run_pgn_validator.py jest właściwym skryptem,
z tym, że w pierwszym udostępnia funkcję main a w drugim
bezpośrednio uruchamia odpowiedni kod. Wybór jednej z tych konwencji
jest już kwestią stylu programowania.
Drugi wariant zapewnia dodatkową metodę uruchamiania. Użytkownik może napisać:
$ python -m mekk.chess.run_pgn_validator <opcje>
Katalog tests
Pliki unit-testów, testujące rozmaite funkcje biblioteki.
W typowych przypadkach będziemy tu mieli serię plików test_cośtam.py,
nawiązujących nazwami do weryfikowanych plików źródłowych.
Katalog doc
Dokumentacja. Od notatek developerskich i planów po podręczniki użytkownika.
Przy zachowaniu pewnych konwencji i pisaniu w składni ReStructuredText można generować wynikową dokumentację w formatach HTML czy PDF.
Służy do tego Sphinx ale o nim nie tym razem.
Katalog samples
Przydatne tylko, gdy piszemy bibliotekę. Kilka skryptów prezentujących charakterystyczne przykłady jej użycia.
Zdarza się, że programiści odsyłają po przykłady użycia do unit-testów. To nie jest dobra metoda. Celem unit-testów jest weryfikacja poprawności działania kodu w różnych - zwłaszcza brzegowych - wypadkach. Celem przykładu użycia jest dostarczenie czytelnego dla programisty typowego kodu ilustrującego naturalny sposób używania biblioteki, w miarę możliwości nadającego się do skopiowania i rozwijania.
Katalogi build i dist
Katalogi build i dist są tworzone i wykorzystywane
przez SetupTools w trakcie budowania dystrybucji modułu.
Zostaną stworzone automatycznie, wspominam o nich bo ... kiedyś
założyłem swój własny katalog build z pomocniczymi skryptami.
Obie nazwy należy traktować jako zastrzeżone.
build jest katalogiem roboczym, w dist są odkładane gotowe
pakiety dystrybucyjne.
Pliki setup.* i README.txt
Plik setup.py zawiera wszystkie istotne ustawienia związane
z instalacją modułu, począwszy od wykazu instalowanych plików.
Skomentowany przykład:
# -*- coding: utf-8 -*-
# (c) 2008, Jan Kowalski
from setuptools import setup, find_packages
# Numer wersji. Należy przestawić przed każdym buildem
# (albo wykorzystać jakąś automatykę powiązaną
# z narzędziem kontroli wersji)
version = '0.3.0'
setup(
###################################################
# Metryczka
###################################################
#
# Nazwa pakietu i numer wersji
name = 'mekk.chess',
version = version,
#
# Informacje o autorze i miejscu publikacji modułu
author = 'Jan Kowalski',
author_email = 'Jan.Kowalski@gmail.com',
url = 'http://jakis.tam.serwis.pl/python/chess',
#
###################################################
# Główne ustawienia dystrybucyjne
###################################################
#
# Gdzie są źródła
package_dir = {'':'src'},
#
# Jakie pliki dystrybuujemy. Flaga exclude nie jest
# tu niezbędna jeśli stosujemy konwencję src
packages = find_packages('src',
exclude=['samples', 'tests']),
#
# Lista pakietów będących namespace
namespace_packages = ['mekk'],
#
# Sposób uruchamiania unit-testów
test_suite = 'nose.collector',
#
# Czy biblioteka może być instalowana w formie skompresowanej
# (patrz komentarz niżej)
zip_safe = False,
#
# Wymagane moduły zależne. Przed zainstalowaniem tej
# biblioteki easy_install zainstaluje je wszystkie, w razie
# potrzeby ściągając je z PyPi lub z zadanego miejsca.
install_requires = [
'lxml>=2.0.0', 'Twisted>=8.1.0', 'simplejson',
'mekk.util>=0.3.0',
],
#
# Moduły uruchamiania testów
tests_require = [
'nose',
],
#
# Przykład dołączania do dystrybucji plików nie-pythonowych.
# Tutaj - zostaną zabrane wszystkie pliki o rozszerzeniu
# .eco z katalogu mekk/chess. W ten sposób opisujemy
# pliki pomocnicze
package_data = {
'mekk.chess' : ['*.eco'],
},
#
# Czy dystrybuujemy jakieś skrypty/programy
scripts = [
"scripts/validate_pgn",
"scripts/pgncat",
],
#
###################################################
# Dane opisowe i licencja
###################################################
#
# Pola te są istotne, jeśli chcemy publikować bibliotekę
# na PyPi - i ogólniej, udostępniać ją innym. Przy
# użytku własnym lub wewnętrznym nie są konieczne.
#
# W razie publikacji na licencji GPL czy BSD warto
# dodać jej treść w formie pliku LICENSE.txt.
#
description = "Parsing and generating PGN files",
long_description = open("README.txt").read(),
keywords = 'chess,pgn',
classifiers = [
"Programming Language :: Python",
"Intended Audience :: Developers",
"Topic :: Software Development :: Libraries :: Python Modules",
"Environment :: Console",
"Development Status :: 2 - Pre-Alpha",
"License :: OSI Approved :: GNU General Public License (GPL)",
],
license = 'GNU General Public License (GPL)',
)
Powyższy przykład objął tylko elementy związane z dystrybucją czysto pythonowego kodu. Mogą wystąpić także wpisy dotyczące kompilacji binarnych rozszerzeń pisanych w C czy C++, deklaracje punktów wejścia i wiele innych.
Punkty wejścia
Punkty wejścia są fajnym mechanizmem obsługi wtyczek, pozwalającym
skryptom i programom automatycznie wykrywać dostępne w systemie
rozszerzenia. Objaśnię to na przykładzie. Gdybym dodał
w wywołaniu setup następujący parametr:
entry_points=""" [paste.paster_command] pgncontroller = mekk.chess.paste_commands:PgnControllerCommand [paste.paster_create_template] gamepublisher = mekk.chess.paste_templates:GamePublisherTemplate [babel.extractors] mekkchess = mekk.chess.babelplugin:extract """,
to program paster zyskałby nową
komendę (paster pgncontroller), korzystającą z mojej klasy
PgnControllerCommand z pliku src/mekk/chess/paste_commands.py,
oraz nowy szablon aplikacji (paster create gamepublisher),
generowany przy pomocy mojej klasy GamePublisherTemplate.
Przy tym, stałoby się to bez potrzeby jakiejkolwiek konfiguracji
samego programu paster.
Dokładnie tak wpinają się w pastera Pylons czy TurboGears.
Jak to działa? Skrypt lub biblioteka może (przy pomocy API
SetupTools)
spytać o zainstalowane w systemie
punkty wejścia o zadanej nazwie - czyli np. paster zadaje
pytanie jakie mamy w systemie punkty wejścia dla paste.paster_command?
Odpowiedź jest generowana na bazie powyższych deklaracji.
Potem program robi z odpowiedzią to, co uzna za stosowne (zazwyczaj
ładuje odpowiednie moduły i klasy).
Oczywiście aby to działało, moje klasy musiałyby spełniać wymagania co
do API danych pakietów (dla każdego z powyższych przykładów
specyficzne i zupełnie inne). Konwencja entry_points służy wyłącznie
do szukania.
Mechanizm jest całkiem popularny, wtyczek przy pomocy zapisów
entry_points szukają choćby nose (dodatkowe
mechanizmy wyszukiwania i uruchamiania testów), python.templating (języki
szablonów), sqlalchemy (interfejsy bazodanowe),
same setuptools (dodatkowe komendy okołoinstalacyjne),
a nawet Trac. Specjalne punkty console_scripts i gui_scripts
pozwalają zaś generować przy instalacji skrypty bez ich ręcznego
pisania (są alternatywą do tworzenia katalogu scripts).
zip_safe
Jeszcze wzmianka o fladze zip_safe. Ustawienie jej na True pozwala
instalatorowi na instalowanie pakietu bez rozpakowywania, wyłącznie
w formie pliku .egg (tj. spakowanego zipa). Możemy tak robić, jeśli:
- biblioteka nie zawiera żadnych binarnych rozszerzeń,
- biblioteka nie odwołuje się do swoich własnych plików zakładając,
że są plikami dyskowymi (w powyższym przykładzie któraś z klas
mogłaby próbować otworzyć plik
opening.ecoszukając go we własnym katalogu, przy instalacji spakowanej wersji to się nie uda, można to rozwiązać używająć APIpkg_resourceszamiast bezpośredniego dostępu do plików i katalogów).
Plik setup.cfg
Plik setup.cfg nie jest obowiązkowy, zawiera zwykle różne drobne
ustawienia okołoinstalacyjne. Przykład kilku częściej stosowanych flag:
[egg_info] tag_build = .dev [easy_install] find_links = http://moj.sajt.pl/download/pymodules/ [nosetests] verbosity = 0 with-doctest = 1 detailed-errors = 1 with-coverage = 1
Flaga tag_build dokleja zadane słówko do numeru wersji w nazwie tworzonego
przy budowie dystrybucji pliku .egg czy .tar.gz.
Blok nosetests pozwala skonfigurować sposób uruchamiania unit-testów.
Adres find_links zadaje alternatywne (inne niż PyPi) miejsce
poszukiwania modułów zależnych. Użyjemy tego chcąc zrobić własną
stronę z listą dystrybuowanych modułów. Taka lista może wyglądać
dowolnie, byle linkowała do wszystkich potrzebnych plików. W
szczególności może to być autogenerowany przez serwer WWW indeks
katalogu albo dowolna strona HTML z listą linków.
Pierwotną ideą
setup.cfgbyło umożliwienie nadmazywania wybranych ustawień zsetup.pybez modyfikowania tego ostatniego.
README.txt to prosty krótki opis modułu - do czego służy, kto jest
autorem, gdzie jest udokumentowany, gdzie jest główne repozytorium
kodu i strona projektu. Oprócz niego może się przydać LICENSE.txt
z treścią właściwej licencji.
Wykorzystanie
Jak korzystać z tak sprokurowanej hierarchii katalogów?
Praca developerska
Aby interpreter pythona widział biblioteki z takiej hierarchii, musimy dodać je do jego ścieżki. Najprostszym na to sposobem jest użycie polecenia
$ python setup.py develop
co spowoduje widzenie przez pythona mojego katalogu roboczego jako elementu ścieżki.
Technicznie: zostanie stworzony plik
site-packages/mekk.chess.egg-link(zawierający nazwę mojego katalogu ze źródłami) oraz katalog ten zostanie dopisany dosite-packages/easy-install.pth. Reszta to już magia SetupTools i ich styku z pythonem (przede wszystkim - przeszukiwanie miejsc wymienionych w plikueasy-install.pth).
Alternatywnie, możemy pakiet normalnie zainstalować:
$ python setup.py install
wszystkie potrzebne pliki zostaną skopiowane do site-packages i to do nich
będzie się odwoływał interpreter.
W tym wypadku powstanie bądź plik
site-packages/mekk.chess-0.3.0-py2.5.egg(jeśli mamy ustawioną flagęzip_safe), bądź katalog o takiej nazwie zawierający nasz kod. Zostanie też odpowiednio poprawionesite-packages/easy-install.pth.
Warto wiedzieć, że powyższe polecenia można przeplatać (np. można zainstalować
swój moduł przez install a w razie zauważenia problemów napisać
po prostu python setup.py develop i przestawić w ten sposób interpreter
na wersję roboczą).
Przy powyższym modelu pracy bardzo zalecane jest używanie virtualenv, pozwala to uniknąć zaśmiecania folderów systemowych i nie wymaga uprawnień administratora.
Dodajmy też, że oczywiście są niezbędne SetupTools. W razie ich braku: ściągamy ez_setup.py i uruchamiamy ten skrypt.
Oczywiście instalację trzeba powtórzyć dla każdej z bibliotek.
Praca developerska - Eclipse
Powyższa technika nie jest niezbędna przy pracy w Eclipse lub Aptanie
z użyciem
PyDev. Tu wystarczy poustawiać dla wszystkich katalogów
src iż mają typ Python Source, PyDev
będzie je automatycznie dodawał
do pythonowej ścieżki bibliotek przy uruchamianiu i debuggowaniu.
Ustawianie powyższej flagi jest trochę nieintuicyjne:
- klikamy prawym klawiszem myszy na głównym katalogu modułu (np. na
mekk.chess) - w oknie Navigator albo w oknie PyDev Package Explorer- znajdujemy wśród parunastu opcji PyDev - PYTHONPATH, klikamy przycisk Add source folder, rozwijamy drzewko i wybieramy nasz katalog
src.Nie da się tego ustawić prawoklikiem na
src.Dotyczy to tylko otwierania/importowania istniejących bibliotek. Przy tworzeniu nowego modułu za pomocą wizarda PyDev sam zaproponuje właściwe ustawienia.
Dystrybucja
Nasz setup.py daje nam możliwość budowy dystrybucji w kilku różnych formatach.
Najpopularniejszym ostatnio jest
$ python setup.py bdist_egg
tworzący jajko przeznaczone do instalacji easy_install-em, czyli
plik .egg. Można też tworzyć pliki .tar.gz (bdist), a zależnie
od poinstalowanych rozszerzeń SetupTools i inne (z RPM czy
instalatorem dla Windows włącznie).
Jajka instalujemy później robiąc
$ easy_install ~/Download/mekk.chess-0.3.0-py2.5.egg
czy nawet
$ easy_install http://adres.strony.pl/pakiety/mekk.chess-0.3.0-py2.5.egg
Oczywiście można też zainstalować pakiet lokalnie, wspominanym już
$ python setup.py install
Możliwości dystrybucyjne na tym się nie wyczerpują, istnieje kilka narzędzi wspomagających budowę samodzielnych programów. O nich już jednak innym razem (i gdy sam zdecyduję, które z nich jest najporęczniejsze). Inny temat na kiedyś to narzędzia wspomagające zbiorową budowę czy instalację dużej ilości modułów.