Napisałem ostatnio parę rozszerzeń do Mercuriala. Nic szczególnie skomplikowanego, rozwiązania codziennych uciążliwości (np. grupowe definiowanie aliasów albo automatyczne poprawianie numeru wersji przy tagowaniu).
Skoro już zdecydowałem się je opublikować, przydałoby się jakoś zapewniać jakość. A to oznacza przeprowadzanie podstawowych testów funkcjonalności przed każdym release. Co więcej, testy te warto by wykonać na różnych wersjach Mercuriala a nawet na różnych wersjach Pythona.
Przećwiczyłem w tym celu kilka narzędzi, które mogą być przydatne nie tylko w tym zastosowaniu (i nie tylko przy programowaniu w Pythonie).
Cram
Cram pozwala bardzo poręcznie testować skrypty czy programy command-line. Co do zasady jest to zanotowanie wzorcowej sesji shellowej a następnie porównywanie z nią efektów kolejnych uruchomień.
Instalacja
Instalacja Cram to po prostu
pip install --user cram
(i dodanie ~/.local/bin/ do ścieżki).
Zachęcam do przemyszowania (i wypróbowania poniższych przykładów).
Składnia (i proste przykłady)
Prymitywny przykład Cramowego testu (konwencją jest używanie
rozszerzenia .t, poniższy plik nazwałem trivial_cram.t):
$ echo "Ala ma kota a kot jest bardzo zdenerwowany" > ala.txt
$ cat ala.txt
Ala ma kota a kot jest bardzo zdenerwowany
$ bzip2 ala.txt
$ cat ala.txt
cat: ala.txt: No such file or directory
[1]
$ bzcat ala.txt.bz2
Ala ma kota a kot jest bardzo zdenerwowany
(uwaga: wszystkie wiersze powyżej są wcięte na dwie spacje).
Jest to jak widać po prostu zrzut sesji, z drobnym wyjątkiem jakim
jest [1] (zapis nietypowego statusu wykonania komendy).
Test uruchamiamy poleceniem cram:
$ cram -v trivial_cram.t
trivial_cram.t: passed
# Ran 1 tests, 0 skipped, 0 failed.
Jeśli coś zepsuję, cram raportuje, że przebieg sesji się nie
zgadza. Gdy zmieniłem w powyższym teście bzcat na zcat,
otrzymałem:
$ cram -v trivial_cram-buggy.t
trivial_cram-buggy.t: failed
--- trivial_cram-buggy.t
+++ trivial_cram-buggy.t.err
@@ -9,5 +9,7 @@
cat: ala.txt: No such file or directory
[1]
$ zcat ala.txt.bz2
- Ala ma kota a kot jest bardzo zdenerwowany
+
+ gzip: ala.txt.bz2: not in gzip format
+ [1]
# Ran 1 tests, 0 skipped, 1 failed.
Jest też zachowywany plik z pełnym zapisem błędnej sesji (tu był to
trivial_cram-buggy.t.err).
Testy mogą być samodokumentujące i zawierać opisy. Lepsza, równoważna forma powyższego testu może wyglądać tak:
Przygotujmy plik źródłowy:
$ echo "Ala ma kota a kot jest bardzo zdenerwowany" > ala.txt
$ cat ala.txt
Ala ma kota a kot jest bardzo zdenerwowany
Skompresujmy:
$ bzip2 ala.txt
Sprawdźmy czy oryginał zniknął a stworzona kopia zawiera
to, co trzeba:
$ cat ala.txt
cat: ala.txt: No such file or directory
[1]
$ bzcat ala.txt.bz2
Ala ma kota a kot jest bardzo zdenerwowany
(konwencja jest trywialna: linie wcięte na dwie spacje są testem, reszta komentarzem, w ramach testu dolarki zaczynają polecenia a reszta jest zapisem efektów).
Bywa, że test zawiera elementy, które naturalnie się zmieniają. Poniższy test oczywiście nie zadziała poprawnie:
$ pwd
/tmp/cramtests-XfzgUh/variable_cram.t
$ echo "Ala ma kota a kot jest bardzo zdenerwowany" > ala.txt
$ ls -l *
-rw-rw-r-- 1 mekk mekk 43 Dec 6 10:11 ala.txt
$ bzip2 ala.txt
$ ls -l *
-rw-rw-r-- 1 mekk mekk 74 Dec 6 10:11 ala.txt.bz2
bo prezentowany katalog i daty będą za każdym uruchomieniem inne. Można go naprawić następująco
$ pwd
/tmp/cramtests-*/variable_cram.t (glob)
$ echo "Ala ma kota a kot jest bardzo zdenerwowany" > ala.txt
$ ls -l *
-rw-rw-r-- 1 mekk mekk 43 [A-Z][a-z]+ \d+ \d+:\d+ ala\.txt (re)
$ bzip2 ala.txt
$ ls -l *
-rw-rw-r-- 1 mekk mekk 74 [A-Z][a-z]+ \d+ \d+:\d+ ala\.txt\.bz2 (re)
(umieszczenie na końcu wiersza (re) sprawia że jest traktowany
jako wyrażenie regularne a zapis (glob) pozwala zastępować
zmienne fragmenty gwiazdkami)
Ostatnim użytecznym elementem składni jest wsparcie dla poleceń
wielowierszowych. Znak > oznacza, że dany wiersz jest kontynuacją
polecenia:
$ for name in Ala Ola Kot
> do
> echo "Czesc, $name"
> done
Czesc, Ala
Czesc, Ola
Czesc, Kot
Najbardziej użyteczne jest to przy tworzeniu niewielkich plików:
$ cat > test.ini << EOF
> [app]
> verbose = True
> user = Johny Tester
> EOF
Testy są uruchamiane w specjalnie założonym tymczasowym katalogu,
który cram automatycznie sprząta. Można więc bez obaw zakładać
pomocnicze pliki czy katalogi (a także polegać na fakcie, że bieżący
katalog jest na początku testów pusty).
Dokładniej, działa to następująco (co ma znaczenie w przypadku, gdy uruchamiamy parę testów jednym ruchem - np.
cram plik1.t plik2.t plik3.talbocram tests/):
cramtworzy katalog tymczasowy (raz, na początku działania), udostępnia jego lokalizację wszysztkim testom w formie zmiennej$CRAMTMPprzed uruchomieniem każdego testu tworzy nowy podkatalog o nazwie zgodnej z nazwą testu (np.
/tmp/cramtests-OJHwVh/basic.t/) i czyni go katalogiem bieżącymTesty mogą zatem dzielić się między sobą plikami o ile stworzą je w
$CRAMTMP(albo po prostu w..), co czasem jest zaletą a w niektórych przypadkach może być konfudujące.
Jeśli testy potrzebują skorzystać z jakiegoś pliku leżącego w katalogu testów albo
jego pobliżu, mogą użyć zmiennej $TESTDIR. Np.
. $TESTDIR/setup_test_dirs.sh
Realne przykłady
Powyższe testy były czystą ilustracją, ale realne nie są istotnie trudniejsze. Tak wygląda kilka spośród testów jakie zrobiłem dla moich Mercurialowych rozszerzeń:
Parę wskazówek
Efektów poleceń zwykle nie trzeba wpisywać (za wyjątkiem klasycznego TDD). Jeśli funkcjonalność już działa, bardzo szybką metodą jest:
-
napisanie testu (powiedzmy -
basic.t) w którym wpisane są wykonywane polecenia bez żadnych wyników, -
uruchomienie
cramna tym pliku -
użycie jako faktycznego testu pliku … błędów (
mv basic.t.err basic.t), w którymcramumieścił pełny poprawny zrzut sesji.
Efekt ostatniego kroku oczywiście trzeba przejrzeć: raz, by sprawdzić czy to co nagrałem jest poprawne (w końcu mogłem nagrać wystąpienie błędu), dwa, by zamienić na glob-y lub regexp-y części zmienne.
Przyczyn niepowodzenia testu nie trzeba oceniać patrząc na mało czytelny tekstowy diff. O ile rzecz nie jest trywialna, rutynowo robię po prostu
$ kdiff3 basic.t basic.t.err
(plik .err zostaje po nieudanym teście) i mam przyjemny graficzny podgląd.

Zapisów z (re) czy (glob) warto unikać, bo utrudniają
utrzymanie testów (psują obie powyższe konwencje, pliku .err już
nie można skopiować jako aktualizacji testu, a kdiff3 zawierające
je wiersze raportuje jako rozbieżne).
Nie zawsze da się to zrobić ale … sporo można. Wiele poleceń wypisze nazwy plików w formie względnych ścieżek o ile w takiej formie otrzyma parametry. Wymagające wariantowania:
$ find $JAKAS_ZMIENNA_SCIEZKA
można zamienić na
$ cd $JAKAS_ZMIENNA_SCIEZKA
$ find .
Przydatne są też rozmaite opcje konfigurujące format wyniku. Tam, gdzie w moich testach weryfikowałem mercurialową historię, umieszczałem w jego konfiguracji
[ui]
logtemplate = {author}: {desc} / {files}\n
i polecenie hg log przestawało wypisywać daty i identyfikatory changesetów.
Test cramowy jest przetwarzany w formie jednej, ciągłej sesji shellowej.
Można zatem ustawiać zmienne środowiskowe i potem się do nich odwoływać,
można robić cd przechodząc do kolejnych katalogów, można tworzyć
i używać pliki tymczasowe.
Problemy
Brakuje mi w cram-ie chyba tylko dwóch rzeczy.
Tęskno mi do jakiejś formy include, która pozwoliłaby raz napisać
przygotowanie środowiska testu i z kilku testów się do niego
odwołać. Prowokuje to do pisania pojedynczych długich testów zamiast
grup mniejszych (albo do intensywnego copy&paste początków
testów).
Oczywiście można to rozwiązać poza cram-em, czy to wpisując na początku testu coś w stylu
. $TESTDIR/przygotuj.sh
($TESTDIR wskazuje na katalog w którym znajduje się plik .t)
czy to generując uruchamiane pliki .t przez konkatenację ale obie
te formy gubią naturalną czytelność i samoobjaśnialność testu.
Nie znalazłem na razie (acz nie szukałem jeszcze bardzo wnikliwie) metody na oznaczenie całego wiersza wyniku jako opcjonalnego. Mam z tym problem w jednym z testów, który - zależnie od wersji Mercuriala - wypisuje albo nie pewną sugestię.
Tox
Tox powstał przede wszystkim jako narzędzie pozwalające na szybkie testowanie tego samego kodu na wielu różnych wersjach Pythona. Ma jednak, zwłaszcza w nowszych wersjach, znacznie szersze zastosowania, w kontekście moich pluginów ważniejsze od sprawdzania działania na Python2.6 było dla mnie sprawdzanie działania na różnych Mercurialach.
Instalacja
Instalacja Tox to po prostu
pip install --user tox
(i dodanie ~/.local/bin/ do PATH).
Na Debianie/Ubuntu istnieje pakiet
python-toxale jest zwykle dość stary (dla Ubuntu 14.04 jest to tox 1.6, który nie potrafi paru potrzebnych mi rzeczy).
Tox i wiele wersji Pythona
To zastosowanie jest doskonale znane, więc napiszę o nim krótko.
Tworzę kilkuwieszowy plik .tox.ini:
[tox]
envlist = py26,py27,py33,py34
[testenv]
commands=
pip install -r test_requirements.txt
python -m unittest discover tests
i proste
tox
uruchamia testy kolejno na wszystkich wymienionych Pythonach.
Można też wybrać niektóre z nich:
tox -e py27
Bodaj jedyną komplikacją jest tu … skąd wziąć te wszystkie
wersje Pythona. Na Ubuntu
pomocne jest
repozytorium deadsnakes,
którego autor pracowicie pakuje wszelkie wersje pythona (w tej chwili
dostępne są w nim pakiety od python2.3 po python3.5):
$ sudo add-apt-repository ppa:fkrull/deadsnakes
$ sudo apt-get update
$ sudo apt-get install python2.6 python3.3 # itp
(po instalacji odpowiednie pythony są po instalacji dostępne jako /usr/bin/python2.6, /usr/bin/python3.3 itd itp).
Środowisko uruchamiania
Przy uruchamianiu tox-a trzeba pamiętać, że testy wykonują się w
wyizolowanym, osobnym virtualenvie. Nie widać systemowo
poinstalowanych pakietów.
Wymusza to kompletne opisanie środowiska testów. Wszystkie potrzebne
pakiety trzeba albo wymienić jako takie w tox.ini (dyrektywa
deps, patrz niżej) albo jawnie zainstalować przed uruchomieniem
testów (tę rolę pełni pip install w powyższym przykładzie).
Jest to co do zasady dobra rzecz (dodatkowo weryfikuje jakość metaopisu pakietu) ale wymaga pewnej uwagi.
Tox filtruje też zmienne środowiskowe. Można na to wpłynąć
dyrektywami setenv i passenv umieszczanymi w tox.ini), np.
[testenv]
passenv = ORACLE_HOME
setenv =
WORK_DIR = {toxworkdir}/{envname}
HGRCPATH = {toxworkdir}/{envname}/hgrc
({toxworkdir} i {envname} to dwie z kilku predefiniowanych
przez tox wartości do których można się w konfiguracji odwołać).
Sprawa zmiennych wymaga ostrożności. Miałem kiedyś w skrypcie shellowym odpalającym testy
rm -rf $DEVEL_LOGS/mylib(gdzie$DEVEL_LOGSbyło moją zmienną ustawioną na katalog na logi tymczasowe). Nie patrząc zbyt uważnie spróbowałem uruchomić pod tox-em i … odczułem wielką ulgę, że nie było torm -rf $DEVEL_LOGS/*
Katalogiem w którym startuje tox jest normalny katalog roboczy
testowanej biblioteki. Jeśli zatem testy tworzą jakieś tymczasowe
pliki czy katalogi trzeba pilnować by generowały unikalne nazwy
i poprawnie po sobie sprzątały.
Nie tylko per wersja Pythona
Jak już wspominałem, głównym zastosowaniem dla tox-a przy testowaniu moich mercurialowych dodatków było nie testowanie na różnych Pythonach a testowanie na różnych Mercurialach.
Przykładowy plik tox.ini (uwaga: wymaga dość nowego tox),
z komentarzami:
[tox]
;; Minimalna wymagana wersja tox
minversion = 1.8
;; Katalog w którym tox założy swoje virtualenvy i odłoży logi,
;; domyślnie robi to w podkatalogu ``.tox`` w miejscu gdzie leży
;; tox.ini ale to mnie irytowało, wolę by były osobno.
toxworkdir = {homedir}/.tox/work/mercurial/update_version
;; Miejsce cacheowania modułów (wartość domyślna, wpisałem dla pamięci)
distshare = {homedir}/.tox/distshare
;; Pomiń testy wymagające niedostępnej wersji pythona. Dzięki temu
;; nie dostaję błędów na maszynach, na których nie mam pythona 2.6
skip_missing_interpreters = True
;; Lista odpalanych wersji. Tu jest to iloczyn kartezjański
;; wersji Pythona przez wersje Mercuriala
;; (py26-hg27, py26-hg29, … , py27-hg33, py27-hg36).
envlist = {py26,py27}-hg{27,29,30,33,36}
;; Później, by ograniczyć czas, stwierdziłem że wystarczy testować
;; stare mercuriale na starym a nowe na nowym pythonie i zmieniłem
;; na
; envlist = {py26}-{hg27,hg29}, {py27}-hg{30,33,36}
[testenv]
;; Jak się nazywają Pythony w odpowiednich wersjach. Zgodne z
;; defaultem, zapisane dla pamięci.
basepython =
py26: python2.6
py27: python2.7
;; Co trzeba poinstalować w poszczególnych wariantach. Zapisy
;; z prefiksami (py26:, hg27: itd) instalują tylko w wybranych
;; środowiskach.
deps =
mercurial_extension_utils >= 1.0.0
cram >= 0.6
py26: unittest2
hg27: Mercurial>=2.7,<2.8
hg28: Mercurial>=2.8,<2.9
hg29: Mercurial>=2.9,<3.0
hg30: Mercurial>=3.0,<3.1
hg31: Mercurial>=3.1,<3.2
hg32: Mercurial>=3.2,<3.3
hg33: Mercurial>=3.3,<3.4
hg34: Mercurial>=3.4,<3.5
hg35: Mercurial>=3.5,<3.6
hg36: Mercurial>=3.6,<3.7
;; Jak odpalać testy. Poleceń może być też kilka
commands =
cram -v tests
Ten wariant zapewnia mi wykonanie testów dla Mercuriala 2.7, 2.9, 3.0, 3.3 i 3.6, przy czym dla każdej z tych wersji powtarza test zarówno na python 2.6 jak na python 2.7.
Przykładowy efekt uruchomienia:
$ tox
GLOB sdist-make: /home/mekk/DEV_hg/mercurial/update_version/setup.py
py26-hg27 inst-nodeps: /home/mekk/.tox/work/mercurial/update_version/dist/mercurial_update_version-0.5.2.zip
py26-hg27 installed: argparse==1.4.0,cram==0.6,linecache2==1.0.0,mercurial==2.7.2,mercurial-extension-utils==1.1.2,mercurial-update-version==0.5.2,six==1.10.0,traceback2==1.4.0,unittest2==1.1.0,wsgiref==0.1.2
py26-hg27 runtests: PYTHONHASHSEED='1930719463'
py26-hg27 runtests: commands[0] | cram -v tests
tests/dirty.t: passed
tests/file-selection.t: passed
tests/tag-by-version.t: passed
tests/tag-reactions.t: passed
# Ran 4 tests, 0 skipped, 0 failed.
(… ciach podobne dla innych wersji …)
py27-hg36 inst-nodeps: /home/mekk/.tox/work/mercurial/update_version/dist/mercurial_update_version-0.5.2.zip
py27-hg36 installed: argparse==1.2.1,cram==0.6,mercurial==3.6.2,mercurial-extension-utils==1.1.2,mercurial-update-version==0.5.2,wsgiref==0.1.2
py27-hg36 runtests: PYTHONHASHSEED='1930719463'
py27-hg36 runtests: commands[0] | cram -v tests
tests/dirty.t: passed
tests/file-selection.t: passed
tests/tag-by-version.t: passed
tests/tag-reactions.t: passed
# Ran 4 tests, 0 skipped, 0 failed.
___________________________________ summary ____________________________________
py26-hg27: commands succeeded
py26-hg29: commands succeeded
py26-hg30: commands succeeded
py26-hg33: commands succeeded
py26-hg36: commands succeeded
py27-hg27: commands succeeded
py27-hg29: commands succeeded
py27-hg30: commands succeeded
py27-hg33: commands succeeded
py27-hg36: commands succeeded
congratulations :)
W razie gdy coś się nie uda, podsumowanie może wyglądać np. tak::
___________________________________ summary ____________________________________
ERROR: py26-hg27: commands failed
ERROR: py26-hg29: commands failed
py26-hg30: commands succeeded
py26-hg33: commands succeeded
ERROR: py26-hg36: commands failed
ERROR: py27-hg27: commands failed
ERROR: py27-hg29: commands failed
py27-hg30: commands succeeded
py27-hg33: commands succeeded
ERROR: py27-hg36: commands failed
Drone
Ręczne odpalanie testów jest chlubne ale nużące. Dużo lepiej, by stało się to samo.
Tradycyjną odpowiedzią na ten problem są Jenkins czy BuildBot ale dla kodu open-source, otwarcie publikowanego na BitBuckecie, nie trzeba i tego. Za przykładem Travisa obrodziło obecnie usługami typu automatycznie uruchomimy Twoje testy i damy znać, jak poszły.
Kryteria współpracuje z BitBucketem oraz wspiera Pythona zawęziły mi wybór do kilku opcji, z których - trochę na chybił-trafił a trochę ze względu na najprostszy ekran konfiguracyjny - wybrałem drone.io.
Aktywacja testów
Stworzyłem konto (nawet nie musiałem definiować hasła, serwis obsługuje logowanie z BitBucketem albo z GitHubem), udzieliłem zgody na dostęp Drone do moich repozytoriów i zacząłem aktywować dla nich testy.
Zestaw uprawnień, o które Drone prosi, jest dość pokaźny. Ma to uzasadnienie (usługa wspiera także monitorowanie prywatnych repozytoriów, więc musi je widzieć, monitoring wymaga aktywowania w repozytoriach hooka, więc musi móc go do repozytoriów wpisać). Mój kod na BitBuckecie jest jawny a przechowuję go także w innych miejscach, więc nie poświęcałem problemowi wiele uwagi, ale osoby które trzymają tam poważniejsze oprogramowanie mogą rozważyć wydzielenie osobnego konta zawierającego tylko moduły udostępniane Drone.
Dalej działa to niesłychanie prosto. Aktywowanie testów dla konkretnego repozytorium to przejście prostego wizarda, w ramach którego wybieram gdzie mieści się repozytorium (BitBucket, GitHub albo - nie usunięte jeszcze - Google Code), wybieram z listy repozytorium o które mi chodzi:
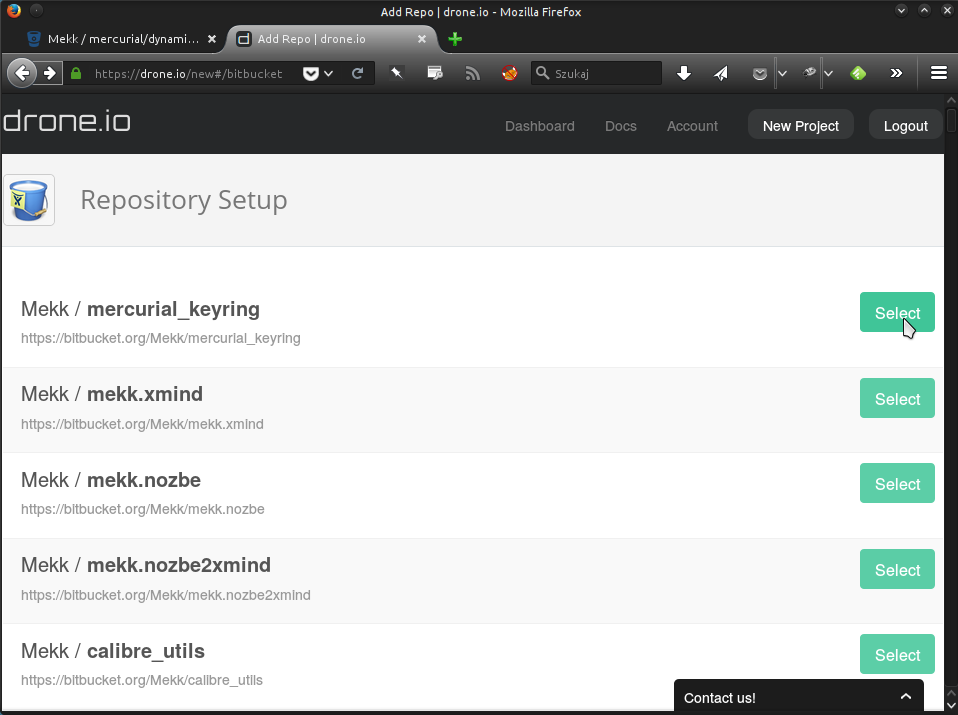
ustalam język programowania (istotny dla środowiska jakie zostanie zapewnione dla uruchamianego testu)

i wpisuję polecenia, które mają zostać użyte do faktycznego uruchomienia testu

Drone sugeruje użycie nosetests, w dokumentacji wspominając
też o py.test, nie ma jednak problemów z używaniem
tox-a. Moje skrypty Drone obecnie wyglądają następująco:
pip -q install tox
tox
a jedynym drobnym ograniczeniem jest niedostępność pythona 2.6 (jest dostępny 2.7 i kilka wersji z linii 3).
Na zakończenie ląduję w ustawieniach projektu:
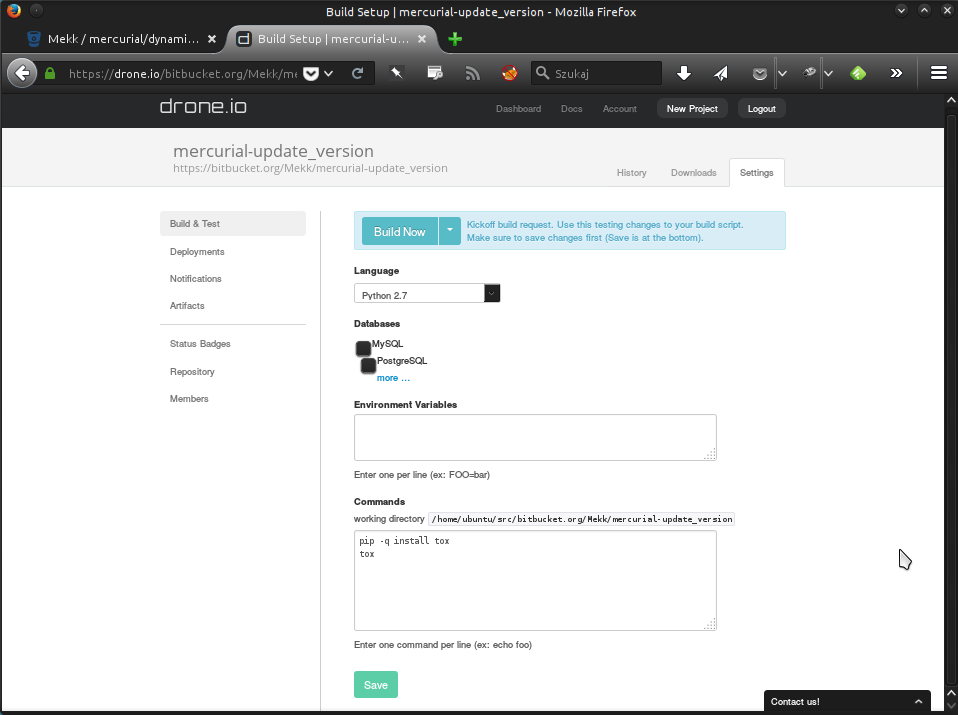
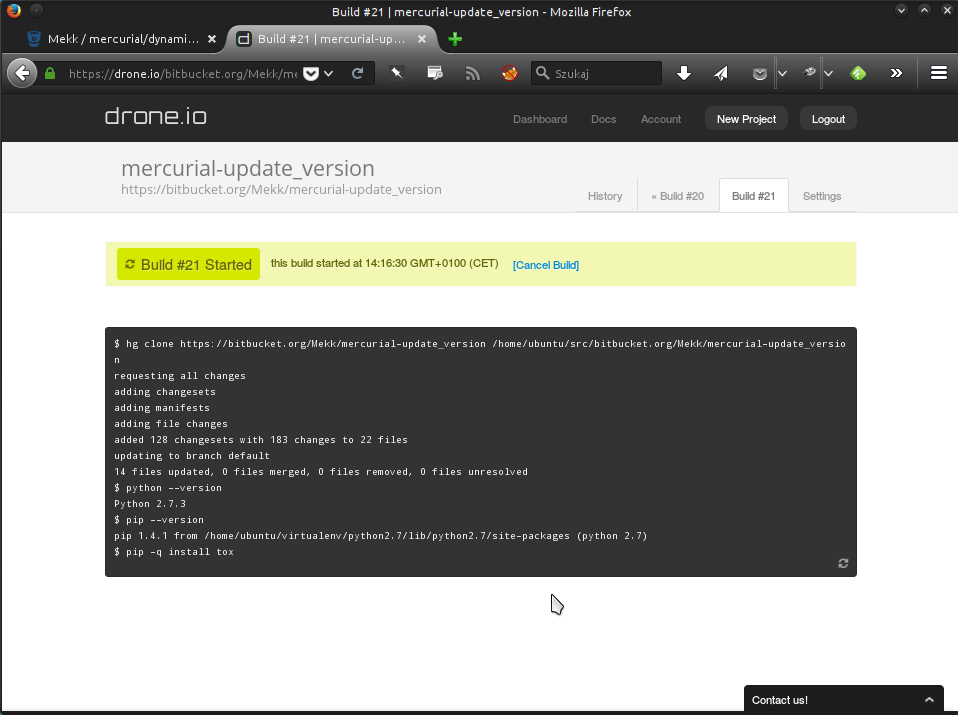
klikam Build i odpowiednie operacje się wykonują, z sympatycznym
przyrostowym podglądem w przeglądarce (strona samoczynnie się uzupełnia
w miarę przebiegu testu).
Ostatnim elementem jest badge, którym można dopiąć do strony
projektu. Jest to po prostu obrazek (nie trzeba żadnych skryptów ani snippetów
HTMLa, wystarczy <img>).

Dalsze używanie
Poza definiowaniem projektów albo diagnozowaniem problemów, serwisu nie trzeba odwiedzać. Drone zauważa nowe commity ilekroć je pchnę na BitBucket i samo uruchamia testy, powiadamiając mnie pocztą o ich wynikach (i odpowiednio aktualizując badge).
Oczywiście maile o udanym teście na dłuższą metę są mało użyteczne, można je wyłączyć - zostawiając notyfikację o niepowodzeniu - w ramach ustawień projektu.
W ramach serwisu dostępna jest historia wykonywanych buildów:

można też podejrzeć jak przebiegał dowolny z nich.
Tutaj screenshot sobie daruję, zamiast tego … proponuję kliknąć dowolny badge (obrazek build passing) na liście moich wtyczek.
Informacje o moich buildach są jawne, bo korzystam z darmowego planu. W planach płatnych można je utajnić.
Okno wyników buildu ma ograniczenie wielkości, gdy w ramach
eksperymentu wrzuciłem do skryptu find ~, udało mi się je
przekroczyć.
Inne funkcjonalności
Python nie jest jedynym ani nawet głównym językiem wspieranym przez Drone. Aktualna lista to wspieranych środowisk to C, C++, Dart, Erlang, Go, Groovy, Haskell, Java, Node.js, PHP, Ruby, Scala.
W razie potrzeby można używać baz danych (PostgreSQL, MySQL, SQLite, MongoDB, CouchDB) a także programów takich jak Memcache, Redis albo Elastic Seach.
Ciekawostką, której chciałbym się kiedyś przyjrzeć, jest wsparcie dla testów wykorzystujących prawdziwą przeglądarkę (firefox lub chrome), uruchamianą w bezgłowej sesji X11.
Drone ma też pewne wsparcie dla deploymentu, może po udanym teście wgrać produkty buildu na taką czy inną produkcję (np. Heroku albo S3).
Luźno myślałem o rozwiązaniu typu jeśli test się udał a testowana wersja jest otagowana, stwórz pakiet i wgraj go na PyPi ale problemem jest autoryzacja. Musiałbym w tej czy innej formie ujawnić Drone moje hasło developera PyPi a to już mnie odstrasza. Gdyby kiedyś PyPi nauczyło się OAuth2 i udostępniania selektywnych uprawnień…
Wnętrzności
Wewnętrznie Drone używa kontenerów Dockerowych, zapewniających izolację uruchomień i powtarzalne ich środowisko.
Kod źródłowy jest otwarty i dostępny: github.com/drone/drone. Ciekawostką jest użycie języka Go.
Podobnie jest dostępna dokumentacja wewnętrzna.
Obie te rzeczy zachęcają do eksperymentów z uruchomieniem własnej instalacji.
Ograniczenia i problemy
Drone jest proste. Testuje zawsze najświeższą wersję (można ewentualnie ograniczyć je do jednego brancha). Nie da się - np. - powiedzieć mu by osobno raportowało testy tipa a osobno testy wersji tagowanych. Nie da się też osobno testować dwóch branchy jednego repozytorium. Nie da się powiązać wyniku z konkretną wersją (i np. flagować lub badgować poszczególnych release).
Środowisko uruchomieniowe jest jakie jest, można w razie potrzeby coś w nim doinstalować ale nie można przesadzić (trzeba uważać na ograniczenia czasu trwania testu czy zużycia przezeń zasobów). Nie ma też żadnych form ustalania harmonogramu, agregacji raportów o błędach ani statystyk zbiorczych.
Testy uruchamiane są na Debianowatym Linuksie, nie ma dostępu do innych środowisk.
Nie ma możliwości awaryjnego dostępu do shella, który pozwoliłby na szczegółową diagnozę problemów (np. wynikających z środowiska uruchamiania). Można to obchodzić, wrzucając do skryptu buildowego polecenia wyświetlające potrzebne informacje, ale cykl popraw skrypt, odpal build, poczekaj na wyniki jest dość powolny.
Poszczególne uruchomienia są bezkontekstowe i nie wydają się zachowywać informacji, nawet tych użytecznych (np. nie mogę raz a dobrze doinstalować czegoś i polegać, że już będzie dostępne).
Bardziej złożone testy mogą zacząć trafiać w ograniczenia czasu działania (w darmowej wersji 15 minut a przy tworzeniu plików produktów do 5 plików o rozmiarze do 10 MB).
W kontekście moich zastosowań to co Drone daje, całkowicie wystarcza, a owa prostota sprawia, że konfiguracja testów jest błyskawiczna.
Good news to fakt, że jeśli zapragnę zmiany albo przerosnę serwis, ewentualna migracja jest trywialna. Cały wysiłek poświęcony na przygotowanie testów nie jest w niczym zależny od Drone. Gdybym kiedyś zapragnął przesiąść się gdzie indziej, będę musiał jedynie odwołać się do tych samych testów na innym serwisie i … zmienić badge.
Alternatywy
Podobnych serwisów jest wiele. Pionierem był Travis (dla mnie nieciekawy, bo mocno i trwale przywiązany do GitHuba).
Parę innych przykładów w kolejności alfabetycznej (lista raczej nie jest kompletna): circleci, CodeShip, Shippable, Semaphore, snap, Wercker.
Rozwiązaniem do własnego uruchomienia może być np. dockunit (nie zapominajmy też o Jenkinsie czy Buildbocie).
Staram się nie tracić zbyt wiele czasu na wybieraniu narzędzi dlatego żadnego z powyższych szerzej nie oglądałem. Niemniej, jeśli ktoś próbował (albo spróbuje) ich użyć, chętnie usłyszę, jak poszło.
Podsumowanie
Dwa wieczory spędzone na konfiguracji i dostosowaniu testów i moje pluginy same się solidnie testują na wielu wersjach Mercuriala, w razie problemów jestem alarmowany mailem, do tego mogłem powiesić na ich stronach estetyczne etykietki. Warto.
Przy tym cały rynek narzędzi wspomagających te lekkie formy Continuous Integration wydaje się być w trakcie gwałtownego wzrostu, można się spodziewać coraz większych i coraz lepszych funkcjonalności. Ich używanie powinno coraz bardziej stawać się normą, tak jak dziś jest nią posiadanie issue-trackera czy repozytorium kodu.
Honorowa wzmianka
… należy się CPAN, a raczej CPAN Testers.
Każdy z perlowych modułów, które opublikowałem na CPAN, automatycznie wpada w sieć testów wykonywanych przez różne osoby, w różnych środowiskach i przy użyciu różnych wersji perla (do tej sieci można też dołączyć, proste doinstalowanie pewnych modułów sprawia, że efekty normalnych instalacji modułów z CPAN są raportowane do CPAN Testers). W razie problemów dostaję ostrzegawcze maile, szczegóły udanych i nieudanych buildów są dostępne z serwisu webowego.
I działa to od wielu, wielu lat…