W dzisiejszym mailu czekały na mnie powiadomienia o smutnej
doli mekk.waw.pl. ServiceUptime skarżył się na niedostępność
strony, MxToolbox alarmował o wyłączonym
serwerze poczty. Przykrość.
Diagnoza
Sprawdziłem pospiesznie czy to nie jakiś ogólny problem z Linode ale nie, strona statusu nie informowała o żadnych problemach. Administracyjny dashboard raportował, że VPS jest włączony i działa. Zagadkę wyjaśniła dopiero ajaksowa konsola:
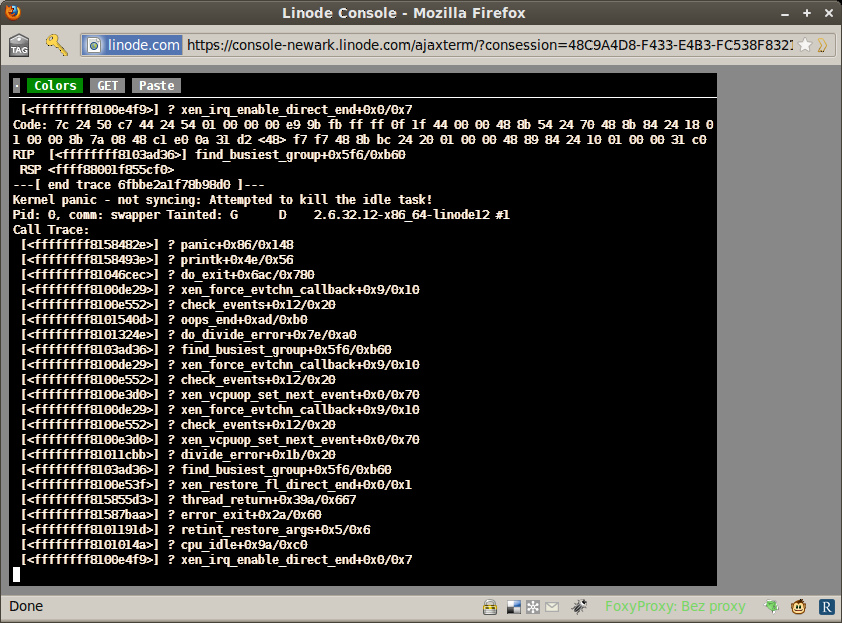
[] ? xen_irq_enable_direct_end+0x0/0x7 Code: 7c 24 50 c7 44 24 54 01 00 00 00 e9 9b fb ff ff 0f 1f 44 00 00 48 8b 54 24 70 48 8b 84 24 18 0 1 00 00 8b 7a 08 48 c1 e0 0a 31 d2 <48> f7 f7 48 8b bc 24 20 01 00 00 48 89 84 24 10 01 00 00 31 c0 RIP [ ] find_busiest_group+0x5f6/0xb60 RSP ---[ end trace 6fbbe2a1f78b98d0 ]--- Kernel panic - not syncing: Attempted to kill the idle task! Pid: 0, comm: swapper Tainted: G D 2.6.32.12-x86_64-linode12 #1 Call Trace: [ ] ? panic+0x86/0x148 [ ] ? printk+0x4e/0x56 [ ] ? do_exit+0x6ac/0x780 [ ] ? xen_force_evtchn_callback+0x9/0x10 [ ] ? check_events+0x12/0x20 [ ] ? oops_end+0xad/0xb0 [ ] ? do_divide_error+0x7e/0xa0 [ ] ? find_busiest_group+0x5f6/0xb60 [ ] ? xen_force_evtchn_callback+0x9/0x10 [ ] ? check_events+0x12/0x20 [ ] ? xen_vcpuop_set_next_event+0x0/0x70 [ ] ? xen_force_evtchn_callback+0x9/0x10 [ ] ? check_events+0x12/0x20 [ ] ? xen_vcpuop_set_next_event+0x0/0x70 [ ] ? divide_error+0x1b/0x20 [ ] ? find_busiest_group+0x5f6/0xb60 [ ] ? xen_restore_fl_direct_end+0x0/0x1 [ ] ? thread_return+0x39a/0x667 [ ] ? error_exit+0x2a/0x60 [ ] ? retint_restore_args+0x5/0x6 [ ] ? cpu_idle+0x9a/0xc0 [ ] ? xen_irq_enable_direct_end+0x0/0x7
Awaria jak awaria, zdarza się, póki jest to raz na dwa lata nie ma powodu do niepokoju. Dla zasady zgłosiłem problem supportowi (ilość funkcji Xena wskazywała, że może go to zainteresować), zrebootowałem maszynę przy pomocy interfejsu administracyjnego i moje pisaniny znów stały się dostępne.
Wymuszenie rebootu
Niedostępnością od 3 do 8 rano nikt poza crawlerami (i być może grającymi w szachy Australijczykami) się nie przejął ale sytuacja mnie zaniepokoiła (ewentualna powtórka w trakcie urlopu byłaby przykra) zastanawiałem się też, czemu nie zadziałał linodowy watchdog.
Support Linode wyjaśnił sprawę (watchdog startuje maszyny po
ewentualnym shutdownie ale zwisów jądra nie wykrywa) a zarazem
podrzucił rozwiązanie - dwa proste ustawienia dla sysctl:
kernel.panic_on_oops = 1 kernel.panic = 1
Pierwsze nakazuje przejść w kernel panic w razie błędu jądra, drugie
ustala, że w razie wystąpienia kernel panic po jednej sekundzie
należy wykonać reboot. Szczegółowy opis obu jest w dokumentacji jądra
(na Debianie/Ubuntu w /usr/share/doc/linux-doc/sysctl/kernel.txt.gz).
Zapewne powinienem znać i stosować te parametry od dawna... Usprawiedliwia mnie trochę to, że oopsa na serwerze nie widziałem od wielu lat.
Zapisałem powyższe dwie linijki w /etc/sysctl.d/99-reboot-on-panic.conf
(równie dobrze można je wpisać do /etc/sysctl.conf ale osobny plik
to jeden mniej konflikt przy upgrade), aktywowałem parametry
dla bieżącej sesji:
$ sudo sysctl -p /etc/sysctl.d/99-reboot-on-panic.conf
i zweryfikowałem czy są poprawnie ustawione
$ sysctl -n -e kernel.panic 1 $ sysctl -n -e kernel.panic_on_oops 1
Problem z głowy. I czynność do zapamiętania przy ewentualnej wstępnej konfiguracji następnego VPS.
Do ewentualnego rozważenia jest jeszcze trzecia flaga,
vm.panic_on_oom(czyli zgłoszenie kernel panic w razie braku pamięci). Na ile sensowne jest jej stosowanie - zależy od konfiguracji maszyny, w szczególności - od tego, czy istotne procesy są w razie zabicia restartowane (jeśli nie, automatyczny reboot przy braku pamięci może mieć sens).
Alerty
Sprawa jest dobrym pretekstem, by zachęcić do używania zewnętrznych narzędzi monitorujących i alarmujących. Zwłaszcza dla autora małego serwisu są ogromną pomocą.
Jest ich masa, szczegółowo recenzować nie czuję się na siłach, sam od wielu lat używam ServiceUptime (monitoring website) a od kiedy ważną pocztę przepuszczam przez własną domenę także MxToolbox (monitoring serwera email). Włączę sobie jeszcze PingDom który w darmowej ofercie potrafi robić testy co 5 minut (inne darmowe usługi to raczej raz na 30-60 minut albo i rzadziej).
Kluczowe różnice to wspominana częstotliwość testów, dostępność i jakość raportów historycznych, ilość i lokalizacja serwerów testujących, rodzaje usług jakie mogą być monitorowane (oprócz weba i poczty także np. ftp czy ssh), nie-emailowe formy notyfikacji (np. SMS) a przy większych serwisach - cena za wersję płatną.
Usługa powinna wyglądać poważnie. Zdarzył mi się serwis (nazwy już nie pamiętam) który, póki go nie wyłączyłem, parę razy w tygodniu alarmował mnie o niedostępności strony, choć działała poprawnie, a były to jego własne problemy z siecią.
Uwaga banalna: emaile ostrzegawcze trzeba odbierać na konto działające poza obserwowaną maszyną - by w razie jej awarii mimo wszystko zostały dostarczone.
Laurka
Przy okazji pozwolę sobie dorzucić kolejną laurkę dla Linode.
Dwa tygodnie temu znowu poprawili plany - tym razem dodając RAM. W efekcie VPS, który kupowałem jako 256MB RAM + 10GB dysku dzisiaj, bez żadnych dopłat z mojej strony, ma 512MB RAM i 16 GB dysku.